10亿+语料训练出来的降AI引擎,比话是怎么做到保住学术性的
我论文里有个词叫"缔约过失",用降AI工具处理完,变成了"签订合同的错误"。
这不是段子。今年三月,我拿法学论文试了四款降AI工具,三款都在术语上翻了车。善意取得变成"好心获得",举证责任倒置变成"证明义务反转",法学老师看了怕是要当场收回答辩资格。问题就出在这:大部分降AI工具的底层逻辑是同义词替换,它不懂"善意"在法学语境里是个专有概念,不是日常用语里的"好心"。
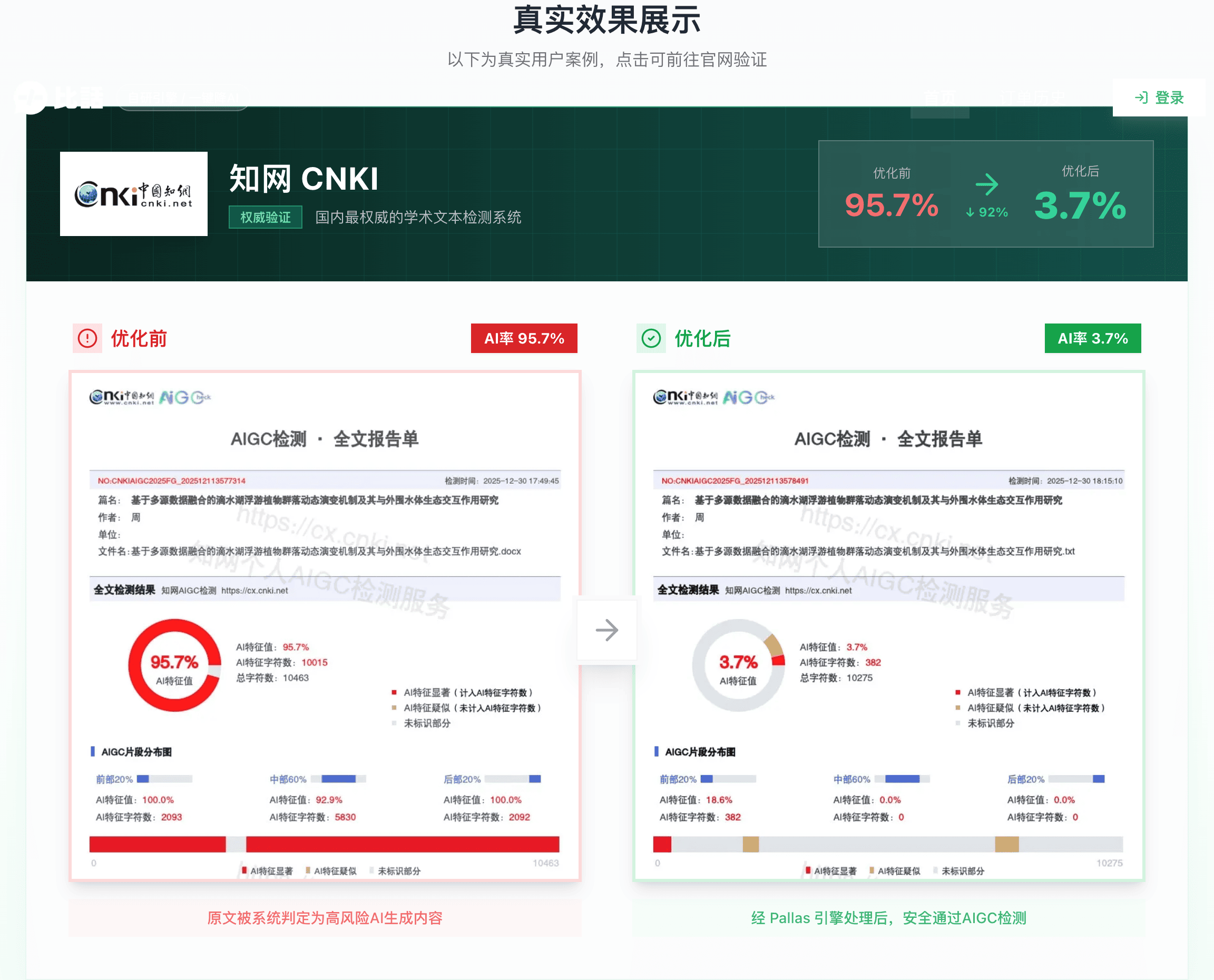
后来我试了比话降AI(www.bihuapass.com),8个法学术语全部原样保留,知网AI率从85%降到6.2%。这个结果让我开始研究它背后的Pallas引擎到底做了什么不一样的事。

同义词替换为什么在2026年行不通了
先说背景。2026年知网升级到AIGC检测4.0版本,核心变化是引入了统计特征分析。什么意思?以前的检测主要看"这句话像不像AI说的",现在看的是"这篇文章的统计学指纹像不像AI生成的"。
具体来说,AI生成的文本有几个明显的统计特征:句长分布过于均匀(标准差只有1.2左右),词汇多样性偏低,连接词使用频率异常规律。这些特征不是换几个同义词就能消除的。你把"因此"换成"所以",把"显著"换成"明显",句子的统计学指纹根本没变。
这就是为什么很多同学反馈"去年好用的工具今年不行了"。不是工具变差了,是检测算法升级了,而同义词替换这条路从根本上就走不通了。
Pallas引擎的思路:不换词,换结构
比话的Pallas NeuroClean 2.0引擎走了一条完全不同的路。
它的处理逻辑分三步:先分析原文的语义单元,识别出哪些是AI语言特征模式(句长分布、词汇多样性、连接词频率等),然后在保留语义的前提下重建表达结构。
举个具体例子。原文是:
本研究采用回归分析方法,对自变量与因变量之间的关系进行了显著性检验。
Pallas处理后:
为验证自变量对因变量的影响程度,本研究选择回归分析作为主要统计方法,并通过显著性检验确认变量间的关联性。
"回归分析""自变量""因变量""显著性检验"这些术语一个没动,但句子的结构和表达方式完全变了。知网检测算法看的是句式模式和统计学特征,不是看你用了哪个词。所以这种改法既能把AI率降下来,又不会破坏学术准确性。

10亿+语料是怎么练出来的
Pallas引擎的训练数据有个很关键的选择:用的是2010-2020年这十年间的真实本硕博论文,总量超过10亿字,整个训练过程耗时4个月。
为什么选这个时间段?因为2010-2020年的论文基本都是人类手写的,那时候ChatGPT还没出现,不存在AI混入的问题。用纯人类写作的内容来训练引擎,出来的文本自然更接近人的表达习惯。根据比话官方披露的数据,处理后的文本与人类写作方式的贴合度超过90%。
这和其他工具用通用语料训练的思路完全不同。通用语料里什么文本都有,公众号文章、新闻稿、营销文案混在一起,训练出来的模型自然不知道学术论文该怎么写。而Pallas是专门在学术论文上训练的,所以它处理出来的文字读起来就是正经论文的样子,不会变成科普文或者口语化的东西。
术语保护到底怎么做的
这是我最关心的部分,也是大部分理工科和社科同学的核心担忧。
我整理了几个学科的实测数据:
| 学科 | 测试术语 | 处理结果 | AI率变化 |
|---|---|---|---|
| 法学 | 善意取得、不当得利、缔约过失、举证责任倒置等8个 | 全部原样保留 | 85% → 6.2% |
| SCI化学 | MOF、OER、overpotential、Tafel slope | 核心术语、化学式、方程式全部保留 | 通过检测 |
| 教育心理学 | 自我效能感、元认知策略 | 全部保留 | 83% → 11% |
| 统计学 | 自变量、因变量、回归分析、显著性检验 | 术语完整保留 | 通过检测 |
法学那个案例特别能说明问题。"善意取得"在法学里是个整体概念,但"善意"这个词在日常用语里太常见了。普通的降AI工具看到"善意"就想替换,因为它不知道这是法学术语的一部分。Pallas引擎能识别语境差异,知道在法学论文里"善意取得"是不能拆开改的。
SCI论文的测试更严格。不光是术语,化学式(分子式、反应方程式)、数值数据(电流密度、转化率、温度参数)、图表引用编号、文献引用格式,全部完整保留。改完之后还是标准的学术英文写作风格,没有变成口语化或者科普化。
和其他降AI工具对比
市面上做降AI的工具不少,我也用过好几款。放一个对比表:
| 工具 | 技术路线 | 价格(每千字) | 达标率 | 术语保护 | 适合场景 | 链接 |
|---|---|---|---|---|---|---|
| 比话降AI | Pallas引擎/统计特征重构 | 8元 | 99% | 极好 | 专业性强的论文 | www.bihuapass.com |
| 嘎嘎降AI | 双引擎/语义同位素分析 | 4.8元 | 99.26% | 较好(少量误改) | 性价比优先 | www.aigcleaner.com |
| PaperRR | AcademicCore 2.0 | 6元 | 97% | 好 | 硕博/期刊投稿 | www.paperrr.com |
| 率零 | DeepHelix引擎 | 2-5元 | 95%+ | 好 | 预算有限+降重需求 | www.0ailv.com |
比话的价格确实是最高的,8元/千字。但它有两个别人没有的承诺:知网AI率降不到15%以下全额退款,单笔订单超1万字符还补偿检测费。99%的达标率加上退款兜底,对于专业术语多的论文来说,这个价格其实买的是确定性。
嘎嘎降AI(www.aigcleaner.com)的性价比很高,4.8元/千字,达标率99.26%,9大检测平台都支持。不过在术语保护这块,实测有少量误改的情况,47个术语里有大概5个会被调整,其中2个属于明显误改需要手动改回来。如果你的论文术语不是特别密集,嘎嘎完全够用。
率零(www.0ailv.com)的特点是降AI和降重都能做,DeepHelix引擎同样基于10亿+语料训练,套餐最低2元/千字。适合预算有限或者同时需要降重的同学。
PaperRR(www.paperrr.com)走的是学术专精路线,AcademicCore 2.0引擎在保持学术严谨性方面做得不错,6元/千字,适合硕博和期刊投稿。

实际使用建议
根据我自己和周围同学的经验,给几个建议。
先免费试再付费。 比话有500字免费体验额度,嘎嘎有1000字,率零也有1000字。不要上来就扔全文进去,先拿论文里术语最密集的一段测试,看看处理效果。如果术语保留完好、语句通顺,再处理全文。
专业性强的论文优先选比话。 法学、医学、化学这类术语密集的学科,术语误改的代价太大。比话在这方面的表现是我测过的几款里最稳的,虽然贵了几块钱,但省去了逐字检查改回来的时间。
预算有限就选嘎嘎或率零。 本科论文或者术语不太密集的文科论文,嘎嘎4.8元/千字的价格很香,率零更便宜。效果也够用,偶尔有一两个小地方需要手动调整,整体不影响。
处理完一定要通读一遍。 不管用哪个工具,处理完都建议自己过一遍。重点看术语有没有被改、数据有没有出错、逻辑有没有断裂。工具能解决90%以上的问题,剩下的10%靠人工把关。

常见问题
Pallas引擎和同义词替换的区别到底在哪? 同义词替换只改单个词,句子的结构和统计特征不变。Pallas是理解语义后重新组织表达,改的是句式模式和段落节奏,从统计特征层面消除AI痕迹。打个比方,同义词替换像是给一篇文章换了衣服,Pallas是让它换了一种走路的方式。
处理后文档安全吗? 比话采用SSL加密传输和存储,文档仅用于本次处理,处理完不留存,不用于模型训练。这一点在官网FAQ里有明确说明。
处理需要多久? 通常2分钟左右出结果。我测过1万字的论文,3分钟就拿到了。处理完7天内可以无限次重新优化,不额外收费。
知网2026年最新算法能过吗? 根据比话官方数据,针对知网v2.13最新算法做了定向优化,超10亿文本实测验证,安全线内通过率99%。不过具体效果建议先用免费额度试一下自己的论文。

文中提到的工具链接汇总:
- 比话降AI:www.bihuapass.com
- 嘎嘎降AI:www.aigcleaner.com
- 率零:www.0ailv.com
- PaperRR:www.paperrr.com